Introduction to Reinforcement Learning
in this article we will introduce the main term of the Reinforcement learning and in the following articles we will go deeper in the field and learn a lot of algorithm and Idea.
Reinforcement Learning
(RL) is one of the most exciting fields of Machine Learning
today, and also one of the oldest. It has been around since the 1950s, producing many
interesting applications over the years.
Natural learning , the natural way for human to learn is by interacting with the environment, we can notice that obviously for children from 1–6 years, as we can see in the video below the little boy move around the room and play with all objects in the room trying to learn new things
than directly theorizing about how people or animals learn, we primarily explore idealized
learning situations and evaluate the effectiveness of various learning methods.
Reinforcement learning Agent is learning what to do — how to map situations ( state ) to (actions) which refers to as policy as to maximize a numerical (reward signal). The learner is not told which actions to
take, but instead must discover which actions yield the most reward by trying them.
Reinforcement learning is different from supervised learning, the kind of learning studied in most current research in the field of machine learning. Supervised learning is learning from a training set of labeled examples provided by a knowledgeable external supervisor.
Each example is a description of a situation together with a specification (the label) of the correct action the system should take to that situation, which is often to identify a category to which the situation belongs. The object of this kind of learning is for the system to extrapolate, or generalize, its responses so that it acts correctly in situations not present in the training set. This is an important kind of learning, but alone it is not adequate for learning from interaction. In interactive problems it is often impractical to
obtain examples of desired behavior that are both correct and representative of all the situations in which the agent has to act. In uncharted territory where one would expect learning to be most beneficial an agent must be able to learn from its own experience. Reinforcement learning is also different from what machine learning researchers call unsupervised learning, which is typically about finding structure hidden in collections of unlabeled data.
The terms supervised learning and unsupervised learning would seem
to exhaustively classify machine learning paradigms, but they do not. Although one might be tempted to think of reinforcement learning as a kind of unsupervised learning because it does not rely on examples of correct behavior, reinforcement learning is trying to maximize a reward signal instead of trying to find hidden structure. Uncovering structure in an agent’s experience can certainly be useful in reinforcement learning, but by
itself does not address the reinforcement learning problem of maximizing a reward signal. We therefore consider reinforcement learning to be a third machine learning paradigm, alongside supervised learning and unsupervised learning and perhaps other paradigms.
in the figure below we see the general framework of the Reinforcement Learning approach.
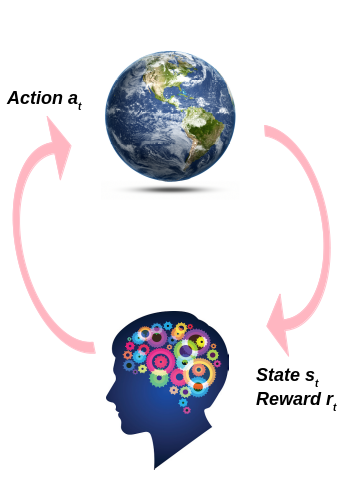
as we can see the Agent do some action in the environment which yields some change in the environment producing a new situation, The agent needs to deal with it, also a reward signal tells the agent the goodness of the action he made.
The Agent :
is a thing (program, robot etc..) that interacts with the environment to learn from the observation (state) he saw, making action lead to maximum reward.
agent examples:
A. The agent can be the program controlling a robot. In this case, the environment is the real world, the agent observes the environment through a set of sensors such as cameras and touch sensors, and its actions consist of sending signals to activate motors. It may be programmed to get positive rewards whenever it approaches the target destination, and negative rewards whenever it wastes time or goes in the wrong direction.
B. The agent can be the program controlling Ms. Pac-Man. In this case, the environment is a simulation of the Atari game, the actions are the nine possible joystick positions (upper left, down, center, and so on), the observations are screenshots,and the rewards are just the game points.
C. Similarly, the agent can be the program playing a board game such as Go.
D. The agent does not have to control a physically (or virtually) moving thing. For example, it can be a smart thermostat, getting positive rewards whenever it is close to the target temperature and saves energy, and negative rewards when humans need to tweak the temperature, so the agent must learn to anticipate human needs.
E. The agent can observe stock market prices and decide how much to buy or sell every second. Rewards are obviously the monetary gains and losses
Policy:
in its simple definition, how we make the decision.
in its simple definition, how we make the decision.
the policy it’s a function that maps from state to action, the agent observes to new state Sₖ the agent make the action Aₖ under policy π.
if we know the best action for all states we know the optimal policy π* which we trying to learn.
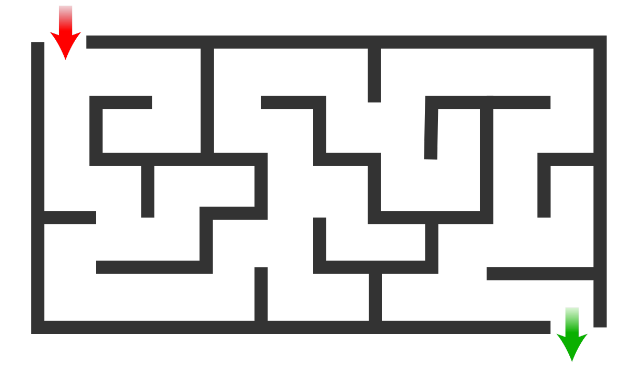
- deterministic π(state)=a which means for each state we have one action to make. the deterministic policy in the stable environment that never change for example let’s say I have a maze and I need to leave it as fast as I can after I learn the best action for each state that action will never change because the world is stable
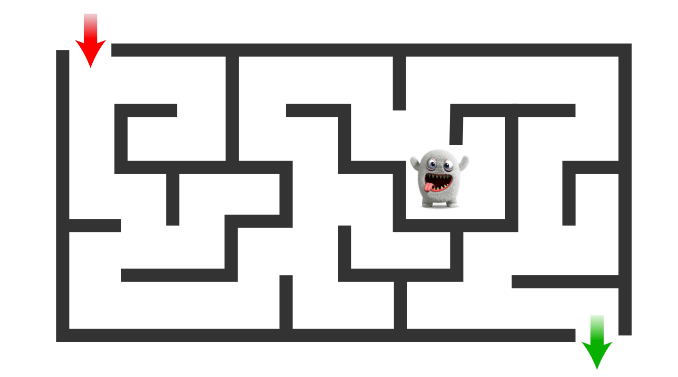
2. stochastic policy π(a|state) = P (a t = a|s t = state) which means for each state there is a probability distribution over actions. so what is the best action to make if the state is changing over time?.
for example, as in the previous example, we have a maze but this time we have some monsters that move in the maze and will kill the player if they share the same block. so the player should avoid that even if he makes the path longer
Rewards signal:
predict the immediate benefits from taking action Aₜ at state Sₜ, so its function defines the goal of a reinforcement learning problem.On each time step, the environment sends to the reinforcement learning Agent a single number called the reward.
The Agent’s sole objective is to maximize the total reward it receives over
the long run. The reward signal thus defines what are the good and bad events for the Agent.
In a biological system, we might think of rewards as analogous to the experiences of pleasure or pain. They are the immediate and defining features of the problem faced by the agent. The reward signal is the primary basis for altering the policy; if an action selected by the policy is followed by low reward, then the policy may be changed to select some other action in that situation in the future.
In general, reward signals may be stochastic functions of the state S of the environment and the actions A taken.
R(sₜ= s, aₜ= a) = E[rₜ|sₜ= s, aₜ= a]
the reward signal is a very important function because it’s leading the training operation we should be very careful when we create this function because the agent may find a wary to maximize the reward without reaching the Goal. for example, if we create a reward function for a chess master agent that gives a positive reward for each piece I take from the opponent. in this case, the agent
may think the goal is to take the opponent’s piece not checkmates action.
Value function Vπ, V*:
as we say the Rewards signal indicates what is good in the immediate sense, while the Value function
is specified what is good in the long run. Vπ is the expected discounted sum of future rewards (return) under a particular policy π. lets deffine the return as follow.
Gₜ= Rₜ+ γRₜ₊₁ + γ²Rₜ₊₂ + …
we can write the return in recursive form like this:
Gₜ= Rₜ+ γGₜ₊₁
Vπ(Sₜ= s) = E[Gₜ|Sₜ= s]
as we see in the equation above the value function mapping between state and sealer value represents the Important of that state. values indicate the long-term desirability of states after taking into account the states that are
likely to follow and the rewards available in those states. For example, a state might always yield a low immediate reward but still have a high value because it is regularly followed by other states that yield high rewards. Or the reverse could be true.
V* indicates that optimal value function under an optimal policy which means the value of each state it’s greater than any other value function under a different policy.
V*(s) > Vπ(s); s ∈ S where S is the states space.
Discount factors γ:
The discount factor indicates how much we care about the future, the discount factor has value ∈ [0, 1] If the discount factor is close to 0, then future rewards won’t count for much compared to immediate rewards, we call the agent Myopic. Conversely, if the discount factor is close to 1,
then rewards far into the future will count almost as much as immediate rewards, we call the agent Farsighted.
Typical discount factors vary from 0.9 to 0.99. With a discount factor of 0.95, rewards 13 steps
into the future count roughly for half as much as immediate rewards (since 0.95¹³ ≈ 0.5), while with
a discount factor of 0.99, rewards 69 steps into the future count for half as much as immediate rewards.
Model:
This is something that mimics the behavior of the environment, or more generally, that allows
inferences to be made about how the environment will behave.
For example, given a state and action, the model might predict the resultant next state and next
reward.
Models are used for planning, by which we mean any way of deciding on a course of action by
considering possible future situations before they are actually experienced.
Methods for solving reinforcement learning problems that use models and planning are called
model-based methods, as opposed to simpler model-free methods that are explicitly trial and error learners viewed as almost the opposite of planning.
Exploration and Exploitation:
One of the challenges that arise in reinforcement learning, and not in other kinds of learning, is the
trade-off between exploration and exploitation.
Exploration trying new things that might enable the agent to make better decisions in the future, while Exploitation choosing the actions that are expected to yield good reward given past experience.
To obtain a lot of rewards, a reinforcement learning agent must prefer actions that it has tried in the past and found to be effective in producing reward. But to discover such actions, it has to try actions that it has not selected before. The agent has to exploit what it has already experienced in order to obtain the reward, but it also has to explore in order to make better action selections in
the future.we should find a way to balance between these two aspects in order to make good training process.
for example :
if you visit a restaurant which has 20 dishes and you order some dish and found it very delicious if you are satisfied with that plate and don’t try other plates may you miss out more delicious one.
summary
in this article we learn the basic of RL and all term we will use in future. you must read this article very well and understand all information in it if you want to be ready for next article
I hope you find this article useful and I am very sorry If there is any error or Misspelled in the article, Please do not hesitate to contact me, or drop comment to correct things.
Khalil Hennara
Ai Engineer at MISRAJ
Related Blog
Real—world applications of our expertise
We are developing cutting-edge products to transform the world through the power of artificial intelligence.
Request your consultation