مقدمة في التعلم المعزز
في هذه المقالة سوف نقدم المصطلح الرئيسي للتعلم المعزز وفي المقالات التالية سوف نذهب إلى أبعد في هذا المجال ونتعلم الكثير من الخوارزميات والأفكار.
التعلم التعزيزي
يُعد التعلم الآلي (RL) أحد أكثر مجالات التعلم الآلي إثارة للاهتمام
اليوم، كما أنه أحد أقدم المجالات. فقد ظهر منذ الخمسينيات من القرن العشرين، وأنتج العديد من
التطبيقات المثيرة للاهتمام على مر السنين.
التعلم الطبيعي ، الطريقة الطبيعية للإنسان للتعلم هي من خلال التفاعل مع البيئة، يمكننا ملاحظة ذلك بوضوح للأطفال من سن 1 إلى 6 سنوات، كما نرى في الفيديو أدناه، يتحرك الطفل الصغير حول الغرفة ويلعب بكل الأشياء في الغرفة محاولًا تعلم أشياء جديدة
من وضع نظريات مباشرة حول كيفية تعلم الأشخاص أو الحيوانات، فإننا نستكشف في المقام الأول
مواقف التعلم المثالية ونقيم فعالية أساليب التعلم المختلفة.
التعلم التعزيزي يتعلم العميل ما يجب فعله - كيفية ربط المواقف (الحالة) بـ (الإجراءات) والتي يشار إليها بالسياسة لتعظيم (إشارة المكافأة) الرقمية . لا يتم إخبار المتعلم بالإجراءات التي يجب
اتخاذها، ولكن بدلاً من ذلك يجب عليه اكتشاف الإجراءات التي تحقق أكبر قدر من المكافأة من خلال تجربتها.
التعلم التعزيزي يختلف عن التعلم الخاضع للإشراف ، وهو نوع التعلم الذي تمت دراسته في أغلب الأبحاث الحالية في مجال التعلم الآلي. التعلم الخاضع للإشراف هو التعلم من مجموعة تدريبية من الأمثلة المصنفة التي يقدمها مشرف خارجي مطلع.
كل مثال هو وصف لموقف مع تحديد (العلامة) للإجراء الصحيح الذي يجب أن يتخذه النظام في هذا الموقف، والذي غالبًا ما يكون لتحديد الفئة التي ينتمي إليها الموقف. والغرض من هذا النوع من التعلم هو أن يقوم النظام باستقراء أو تعميم استجاباته بحيث يتصرف بشكل صحيح في المواقف غير الموجودة في مجموعة التدريب. هذا نوع مهم من التعلم، لكنه وحده لا يكفي للتعلم من التفاعل . في المشكلات التفاعلية، غالبًا ما يكون من غير العملي
الحصول على أمثلة للسلوك المرغوب فيه والتي تكون صحيحة وتمثل جميع المواقف التي يتعين على العميل التصرف فيها. في منطقة مجهولة حيث يتوقع المرء أن يكون التعلم مفيدًا للغاية، يجب أن يكون العميل قادرًا على التعلم من تجربته الخاصة. يختلف التعلم التعزيزي أيضًا عما يسميه باحثو التعلم الآلي التعلم غير الخاضع للإشراف ، والذي يتعلق عادةً بالعثور على بنية مخفية في مجموعات من البيانات غير المسماة.
قد يبدو أن مصطلحي التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف
يصنفان نماذج التعلم الآلي بشكل شامل، ولكن هذا غير صحيح. ورغم أن المرء قد يميل إلى التفكير في التعلم التعزيزي باعتباره نوعًا من التعلم غير الخاضع للإشراف لأنه لا يعتمد على أمثلة للسلوك الصحيح، فإن التعلم التعزيزي يحاول تعظيم إشارة المكافأة بدلاً من محاولة العثور على بنية مخفية. ومن المؤكد أن الكشف عن البنية في تجربة العميل يمكن أن يكون مفيدًا في التعلم التعزيزي، ولكنه في
حد ذاته لا يعالج مشكلة التعلم التعزيزي المتمثلة في تعظيم إشارة المكافأة. لذلك نعتبر التعلم التعزيزي نموذجًا ثالثًا للتعلم الآلي، إلى جانب التعلم الخاضع للإشراف والتعلم غير الخاضع للإشراف وربما نماذج أخرى.
في الشكل أدناه نرى الإطار العام لمنهج التعلم المعزز.
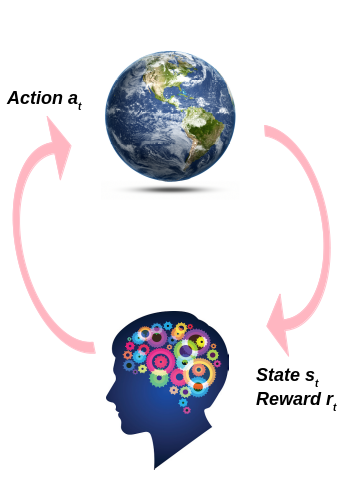
كما نرى أن العميل يقوم ببعض الإجراءات في البيئة مما يؤدي إلى بعض التغيير في البيئة مما ينتج عنه موقف جديد، يحتاج العميل إلى التعامل معه، كما تخبر إشارة المكافأة العميل بجودة الإجراء الذي قام به.
الوكيل :
هو شيء (برنامج، روبوت، الخ..) يتفاعل مع البيئة ليتعلم من الملاحظة (الحالة) التي شاهدها، مما يجعل العمل يؤدي إلى أقصى قدر من المكافأة.
أمثلة الوكيل:
أ. يمكن أن يكون العميل هو البرنامج الذي يتحكم في الروبوت. في هذه الحالة، تكون البيئة هي العالم الحقيقي، ويراقب العميل البيئة من خلال مجموعة من أجهزة الاستشعار مثل الكاميرات وأجهزة استشعار اللمس، وتتألف أفعاله من إرسال إشارات لتنشيط المحركات. قد يتم برمجته للحصول على مكافآت إيجابية كلما اقترب من الوجهة المستهدفة، ومكافآت سلبية كلما أهدر الوقت أو ذهب في الاتجاه الخطأ.
ب. يمكن أن يكون العميل هو البرنامج الذي يتحكم في لعبة Ms. Pac-Man. في هذه الحالة، تكون البيئة عبارة عن محاكاة للعبة Atari، وتكون الإجراءات عبارة عن تسعة أوضاع محتملة لعصا التحكم (أعلى اليسار، أسفل، وسط، وهكذا)، وتكون الملاحظات عبارة عن لقطات شاشة، وتكون المكافآت عبارة عن نقاط اللعبة فقط.
ج. وبالمثل، يمكن أن يكون العميل هو البرنامج الذي يلعب لعبة لوحية مثل لعبة Go.
د. لا يتعين على العميل التحكم في شيء متحرك فعليًا (أو افتراضيًا). على سبيل المثال، يمكن أن يكون منظم حرارة ذكيًا، يحصل على مكافآت إيجابية كلما اقترب من درجة الحرارة المستهدفة ويوفر الطاقة، ومكافآت سلبية عندما يحتاج البشر إلى تعديل درجة الحرارة، لذلك يجب على العميل أن يتعلم توقع الاحتياجات البشرية.
هـ. يستطيع الوكيل مراقبة أسعار سوق الأوراق المالية وتحديد مقدار ما يشتريه أو يبيعه كل ثانية. ومن الواضح أن المكافآت هي المكاسب والخسائر النقدية
سياسة:
في تعريفه البسيط، كيف نتخذ القرار.
في تعريفها البسيط، كيف نتخذ القرار.
السياسة هي دالة تنتقل من الحالة إلى الفعل ، يلاحظ العميل الحالة الجديدة S ₖ، يقوم العميل بالفعل A ₖ بموجب السياسة π .
إذا عرفنا أفضل إجراء لجميع الحالات، فإننا نعرف السياسة المثلى π* التي نحاول تعلمها.
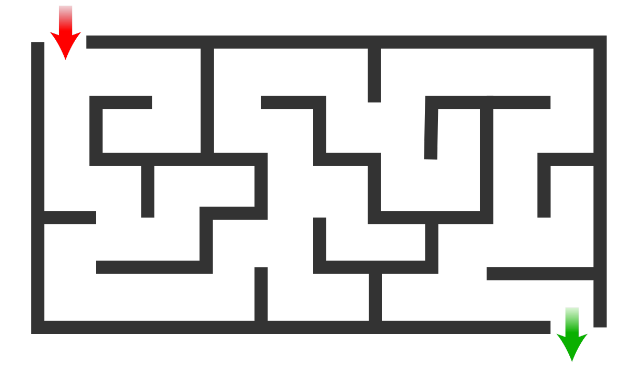
- حتمية π(state)=a وهذا يعني أنه لكل حالة لدينا إجراء واحد يجب القيام به. السياسة الحتمية في البيئة المستقرة التي لا تتغير أبدًا على سبيل المثال، لنفترض أن لدي متاهة وأحتاج إلى تركها بأسرع ما يمكن بعد أن أتعلم أفضل إجراء لكل حالة، لن يتغير هذا الإجراء أبدًا لأن العالم مستقر
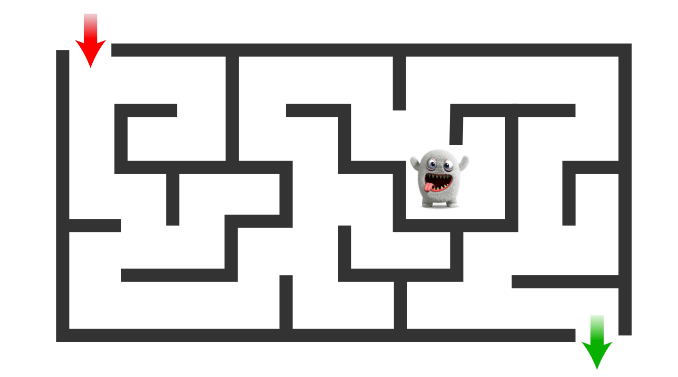
2. سياسة عشوائية π(a|state) = P (at = a|st = state) مما يعني أنه لكل حالة يوجد توزيع احتمالي على الإجراءات. إذن ما هو أفضل إجراء يجب اتخاذه إذا كانت الحالة تتغير بمرور الوقت؟
على سبيل المثال، كما في المثال السابق، لدينا متاهة ولكن هذه المرة لدينا بعض الوحوش التي تتحرك في المتاهة وستقتل اللاعب إذا تقاسما نفس الكتلة. لذا يجب على اللاعب تجنب ذلك حتى لو جعل المسار أطول
إشارة المكافآت:
توقع الفوائد الفورية المترتبة على اتخاذ الإجراء Aₜ في الحالة Sₜ ، وبالتالي فإن وظيفتها تحدد هدف مشكلة التعلم المعزز. في كل خطوة زمنية، ترسل البيئة إلى وكيل التعلم المعزز رقمًا واحدًا يسمى المكافأة.
الهدف الوحيد للوكيل هو تعظيم إجمالي المكافأة التي يتلقاها على
المدى الطويل. وبالتالي، تحدد إشارة المكافأة الأحداث الجيدة والسيئة للوكيل.
في النظام البيولوجي، قد نفكر في المكافآت باعتبارها مماثلة لتجارب المتعة أو الألم. فهي السمات المباشرة والمحددة للمشكلة التي يواجهها العامل. وتشكل إشارة المكافأة الأساس الأساسي لتغيير السياسة؛ فإذا تلا أحد الإجراءات التي تختارها السياسة مكافأة منخفضة، فقد تتغير السياسة لاختيار إجراء آخر في هذا الموقف في المستقبل.
بشكل عام، قد تكون إشارات المكافأة عبارة عن وظائف عشوائية لحالة البيئة S والإجراءات A المتخذة.
R(s ₜ = s، a ₜ = a) = E[r ₜ |s ₜ = s، a ₜ = a]
إشارة المكافأة هي وظيفة مهمة للغاية لأنها تقود عملية التدريب، يجب أن نكون حذرين للغاية عند إنشاء هذه الوظيفة لأن العميل قد يجد صعوبة في تعظيم المكافأة دون الوصول إلى الهدف. على سبيل المثال، إذا أنشأنا وظيفة مكافأة لعميل رئيسي في الشطرنج يعطي مكافأة إيجابية لكل قطعة آخذها من الخصم. في هذه الحالة،
قد يعتقد العميل أن الهدف هو أخذ قطعة الخصم وليس إجراء الكش مات.
دالة القيمة V π , V*:
كما نقول، تشير إشارة المكافآت إلى ما هو جيد بالمعنى الفوري، في حين
تحدد دالة القيمة ما هو جيد في الأمد البعيد. Vπ هو المبلغ المخصوم المتوقع للمكافآت المستقبلية (العائد) بموجب سياسة معينة π. دعنا نحدد العائد على النحو التالي.
Gₜ= Rₜ+ γRₜ₊₁ + γ²Rₜ₊₂ + …
يمكننا كتابة العائد في شكل متكرر مثل هذا:
Gₜ= Rₜ+ γGₜ₊₁
Vπ(Sₜ= ق) = E[Gₜ|Sₜ= ق]
كما نرى في المعادلة أعلاه، فإن تعيين دالة القيمة بين الحالة وقيمة الختم يمثل أهمية تلك الحالة. تشير القيم إلى مدى استصواب الحالات على المدى الطويل بعد مراعاة الحالات التي من
المرجح أن تتبعها والمكافآت المتاحة في تلك الحالات. على سبيل المثال، قد تسفر الحالة دائمًا عن مكافأة فورية منخفضة ولكنها لا تزال تتمتع بقيمة عالية لأنها تتبعها بانتظام حالات أخرى تحقق مكافآت عالية. أو قد يكون العكس صحيحًا.
يشير V * إلى دالة القيمة المثلى في ظل سياسة مثالية مما يعني أن قيمة كل حالة أكبر من أي دالة قيمة أخرى في ظل سياسة مختلفة.
V*(s) > Vπ(s); s ∈ S حيث S هي مساحة الحالات.
عوامل الخصم γ:
يشير عامل الخصم إلى مدى اهتمامنا بالمستقبل، وعامل الخصم له قيمة ∈ [0، 1] إذا كان عامل الخصم قريبًا من 0، فلن تكون المكافآت المستقبلية ذات قيمة كبيرة مقارنة بالمكافآت الفورية، ونسمي العامل قصير النظر . وعلى العكس من ذلك، إذا كان عامل الخصم قريبًا من 1،
فإن المكافآت في المستقبل البعيد ستُحسب تقريبًا بقدر المكافآت الفورية، ونسمي العامل بعيد النظر .
تتراوح عوامل الخصم النموذجية من 0.9 إلى 0.99. مع عامل خصم 0.95، فإن المكافآت على بعد 13 خطوة
في المستقبل تُحسب تقريبًا بنصف قدر المكافآت الفورية (نظرًا لأن 0.95¹³ ≈ 0.5)، بينما مع
عامل خصم 0.99، فإن المكافآت على بعد 69 خطوة في المستقبل تُحسب بنصف قدر المكافآت الفورية.
نموذج:
إن هذا شيء يحاكي سلوك البيئة، أو بشكل عام، يسمح
باستنتاجات حول كيفية تصرف البيئة.
على سبيل المثال، في حالة وفعل معينين، قد يتنبأ النموذج بالحالة التالية والمكافأة التالية الناتجة
.
تُستخدم النماذج للتخطيط، ونعني بذلك أي طريقة لاتخاذ قرار بشأن مسار العمل من خلال
النظر في المواقف المستقبلية المحتملة قبل تجربتها فعليًا.
تُسمى الطرق المستخدمة لحل مشكلات التعلم التعزيزي التي تستخدم النماذج والتخطيط بالطرق
القائمة على النماذج ، على عكس الطرق البسيطة الخالية من النماذج والتي تعتمد بشكل صريح على التجربة والخطأ والتي يُنظر إليها على أنها عكس التخطيط تقريبًا.
الاستكشاف والاستغلال:
إن أحد التحديات التي تنشأ في التعلم التعزيزي، وليس في أنواع أخرى من التعلم، هو
التوازن بين الاستكشاف والاستغلال.
فالاستكشاف يعني تجربة أشياء جديدة قد تمكن العامل من اتخاذ قرارات أفضل في المستقبل، في حين يختار الاستغلال الإجراءات التي من المتوقع أن تسفر عن مكافأة جيدة في ضوء الخبرة السابقة.
للحصول على الكثير من المكافآت، يجب على وكيل التعلم التعزيزي تفضيل الإجراءات التي جربها في الماضي ووجد أنها فعالة في إنتاج المكافأة. ولكن لاكتشاف مثل هذه الإجراءات، يجب عليه تجربة إجراءات لم يختارها من قبل. يجب على الوكيل استغلال ما اختبره بالفعل من أجل الحصول على المكافأة، ولكن يجب عليه أيضًا الاستكشاف من أجل إجراء اختيارات أفضل للإجراءات في
المستقبل. يجب أن نجد طريقة للموازنة بين هذين الجانبين من أجل إجراء عملية تدريب جيدة.
على سبيل المثال:
إذا قمت بزيارة مطعم يقدم 20 طبق وطلبت بعض الأطباق ووجدتها لذيذة جدًا، إذا كنت راضيًا عن هذا الطبق ولم تجرب أطباقًا أخرى فقد يفوتك طبق آخر لذيذ.
ملخص
في هذه المقالة نتعلم أساسيات التعلم العميق وجميع المصطلحات التي سنستخدمها في المستقبل. يجب عليك قراءة هذه المقالة جيدًا وفهم جميع المعلومات الموجودة فيها إذا كنت تريد أن تكون مستعدًا للمقالة التالية
آمل أن تجد هذه المقالة مفيدة وأنا آسف للغاية إذا كان هناك أي خطأ أو خطأ إملائي في المقالة، فلا تتردد في الاتصال بي، أو ترك تعليق لتصحيح الأمور.
خليل حنارة
مهندس ذكاء اصطناعي في مسراج
مقالات ذات صلة
الحلول الفعالة هي مجالنا
نحن نعمل على تطوير منتجات متطورة لتحويل العالم من خلال قوة الذكاء الاصطناعي.
اطلب استشارتك