Q-learning implementation in Table Form
In This article, we will implementation one of the algorithm we mentioned before, in my opinion, this is the best way to get all details of the algorithm.
I assume that you are already familiar with coding and Python programming language so if you don’t know the basics of coding and python you can not follow this article.
for better understanding try to rewrite the code by your self not just read it.
you can download the full code from the GitHub repository hear.
This is the first article we use code in this course so we will try to keep simple as we can, for this article we use the Frozenlake game.
as for most grid games, the role is very simple I need to crosse the lake without falling into holes.

as we can see in the figure above there is a 2 type of block the *Frozen* one which I can cross over and the *Hole* which leads to death.
in This article, we will implement the full code from the ground while in a later article we will use a framework that makes life easier, so let’s start.
first, let’s import the dependencies. as we mentioned before we will implement the code from zero we will need numpy which you should be familiar with it if you don’t read the first 2 chapters from [3] which is a very good resource for not just learning code but also learning Machine learning concepts. now we will implement the environment. as in figure 2, we will represent the game as a 2D grid, for the frozen block we will represent using F char and H for Holes S for start position and G for the goal.
as we say in the first article for the General RL framework we need an Agent and environment to interact with and we represent the agent in the environment with state and the value or the benefit from doing some action in that state with reward.so we need to project our problem on this framework.
- The agent is the player who make the move on the grid.
- The state is the position of the agent in current time t.
- The reward is 1 if the the agent cross the lake(reach the goal) 0 if not and -1 if we loss (fall in hole)
each problem needs to be modeled in a way, that helps to solve it. one of the most difficult tasks is to find a good reward function that leads the learning processes as we mention in the first lecture.
this problem is in episodic form, which means that each game represents one episode and in each episode, we have many steps, and for each episode, there is a two-terminal state which is win or loss so each episode will end after numbers of steps.
now we can start the code.
we define the environment as a class named FrozenLake the init is the constructor we define the Board of the game as fixed board for simplicity but you can try to make changeable
the *pos* is the current position,*N* is the dimension of the board, and *actions_rep* is just to show the action index.
the reset function is for resetting the game for the initial state and we need to call this function each time I need to start a new game.
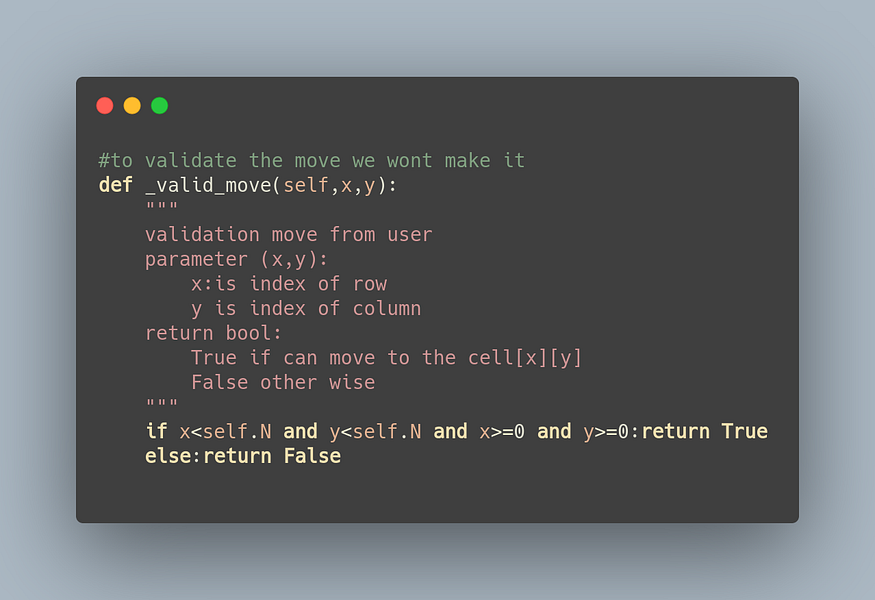
in valid_move is for check if action is valid, The action is valid if and only if occur on the bored so if I do an action lead to the out of bounds it’s not a valid move.
#this one creat the step and return obs,reward,done
def step(self,action):
"""
this function take an action and reutun the state of game
parameter:
action=range(4)
{0:Up,1:Down,2:right,3:left}
return :(state,reward,done)
state:the new state is in range [0,15]
reward 0 if not finish -1 if he loss 1 if we reach the Goale
done False while not (win or loss)
"""
reward=-1
done=False
if action==0:
#go Up
if self._valid_move(self.pos[0]-1,self.pos[1]):
if self.grid[self.pos[0]-1][self.pos[1]]=='H':
reward=-1
done=True
elif self.grid[self.pos[0]-1][self.pos[1]]=='G':
reward=1
done=True
else:
reward=0
done=False
self.grid[self.pos[0]-1][self.pos[1]]='*'
self.pos[0]-=1
elif action==1:
#go Down
if self._valid_move(self.pos[0]+1,self.pos[1]):
if self.grid[self.pos[0]+1][self.pos[1]]=='H':
reward=-1
done=True
elif self.grid[self.pos[0]+1][self.pos[1]]=='G':
reward=1
done=True
else:
reward=0
done=False
self.grid[self.pos[0]+1][self.pos[1]]='*'
self.pos[0]+=1
elif action==2:
#go Right
if self._valid_move(self.pos[0],self.pos[1]+1):
if self.grid[self.pos[0]][self.pos[1]+1]=='H':
reward=-1
done=True
elif self.grid[self.pos[0]][self.pos[1]+1]=='G':
reward=1
done=True
else:
reward=0
done=False
self.grid[self.pos[0]][self.pos[1]+1]='*'
self.pos[1]+=1
elif action==3:
#go left
if self._valid_move(self.pos[0],self.pos[1]-1):
if self.grid[self.pos[0]][self.pos[1]-1]=='H':
reward=-1
done=True
elif self.grid[self.pos[0]][self.pos[1]-1]=='G':
reward=1
done=True
else:
reward=0
done=False
self.grid[self.pos[0]][self.pos[1]-1]='*'
self.pos[1]-=1
return (self.pos[0]*self.N+self.pos[1]),reward,done
the step function is the most important one where we implement the logic of the game. this function returns the new state, reward, and if the game finishes or not. the next-state is the new position of the player, the reward is 1 if win 0 if not yet, and -1 if we lose. the done is helping us in Q-learning implementation. in the previous lecture, we say that if the move we made leads to the end of the episode then the value for this action-state is just the immediate reward because there is no next action we can make.
def render(self):
"""
print the Bord of Game
"""
for i in self.grid:
print(i)
The last function in the FrozenLake class is render function which prints the board represent the current position of the agent as ’*’
after we implement the environment we will now write the agent components.
def exploration_policy(epsilon,state,q_tabel):
"""
this function is for random action
we use epsilon policy for random actions selection
return integer number from [0,3] which indecate the action
"""
if np.random.rand()<epsilon:
return np.random.randint(1,4)
else:
return np.argmax(q_tabel[state])
The first component is the policy we define an 𝜖−𝑔𝑟𝑒𝑒𝑑𝑦 policy you can read about this policy form prev lecture.
#inite the Q_value Tabel where the row is the state and column is action we can do
Q_tabel=np.zeros((16,4))
The Q_table is a 2D table where we represent each state with one row and each action with one column.
as we say the state is the current position of the player so there is 16 possible position in the game because the grid in the environment has a 4x4 block, so it has 16 state and we have 4 action to make (up, down, right, left). so in each state, I can make one of 4 actions and I need to learn what action to do in a specific state that leads to max future reward (reach the goal).
some of you notice that what if there is a very high state space (e.g I have 10 million states) its impossible to solve it like this. fortunately, we can solve it using Function Approximation which is the next Lecture.lets get back to the Q-learning algorithm we explain in previous lecture.

# the environment
env=FrozenLake()#learning rate for Q_value algorithem
lr=0.8#the discount factor
gamma=0.95#epsilon for epsilon policy
epsilon=1#number of epoch
epochs=1000#number of step we can do in each game
num_steps=100#the list for save the reward in each game to check how many game we have been win
reward_List=[]
so we need α which is learning rate 𝛾 discount factor 𝑒𝑝𝑖𝑠𝑜𝑑𝑒𝑠 the number of the episode we run the 𝑝𝑜𝑙𝑖𝑐𝑦 and The 𝑄−𝑓𝑢𝑐𝑛𝑡𝑖𝑜𝑛 which we defined earlier. we will also add another parameter which is the steps the number of steps in each episode and that is important here so if the agent takes a long time to cross finish the episode we terminate it. the reward list to show if the agent learning or not.
sum(reward for reward in reward_List if reward==1)/1000
0.743
as we can see we win in 743 game from 1000 game so the implementation is good, and our agent learn to play this game without knowing any things about the world, he learn to play by interact with environment and observing rewards.
def play_game(env,q_tabel):
"""
this is to play a game depending on the Q_tabel that we learn
"""
state=env.reset()
for i in range(15):
action=np.argmax(q_tabel[state,:])
obs,reward,done=env.step(action)
env.render()
if done:
if reward==1:
print('win')
break
else:
print('loss')
break
state=obs
The last thing we define this function for playing game according to Q-table that we learn before.

summary:
in this lecture, we introduce the Q-learning algorithm which is off-policy TD.we train the Agent to play the FrozenLake game without knowing the dynamic model of the world and just from interacting with the environment.
but what about the real-world problem where the state space is very high then we need to twist the algorithm a little to work efficiently.
in the next lecture, we will introduce Function Approximation which is one way to solve this problem.
I hope you find this article useful and I am very sorry If there is any error or Misspelled in the article, Please do not hesitate to contact me, or drop comment to correct things.
Khalil Hennara
Ai Engineer at MISRAJ
Related Blog
Real—world applications of our expertise
We are developing cutting-edge products to transform the world through the power of artificial intelligence.
Request your consultation